By Vsurgemedia | Data Engineering Series
Data quality management tools comparison
Executive Summary:
In 2026, data is the new oil, but for most companies, that oil is contaminated. According to Gartner’s 2025 Data Trends, poor data quality costs organizations an average of $12.9 million annually. Whether you are training a proprietary Large Language Model (LLM) or running a simple email marketing campaign, “Garbage In” inevitably leads to “Garbage Out.”
The market is flooded with legacy tools that were built for a pre-AI world. As a CTO or Data Leader, you are now faced with a critical choice: Do you invest in expensive legacy suites like Informatica, or do you pivot to the new wave of Autonomous AI Data Agents?
This guide provides a brutal, unfiltered data quality management tools comparison, evaluating the giants against the disruptors, and offering a roadmap to fix your data pipeline before it breaks your business.
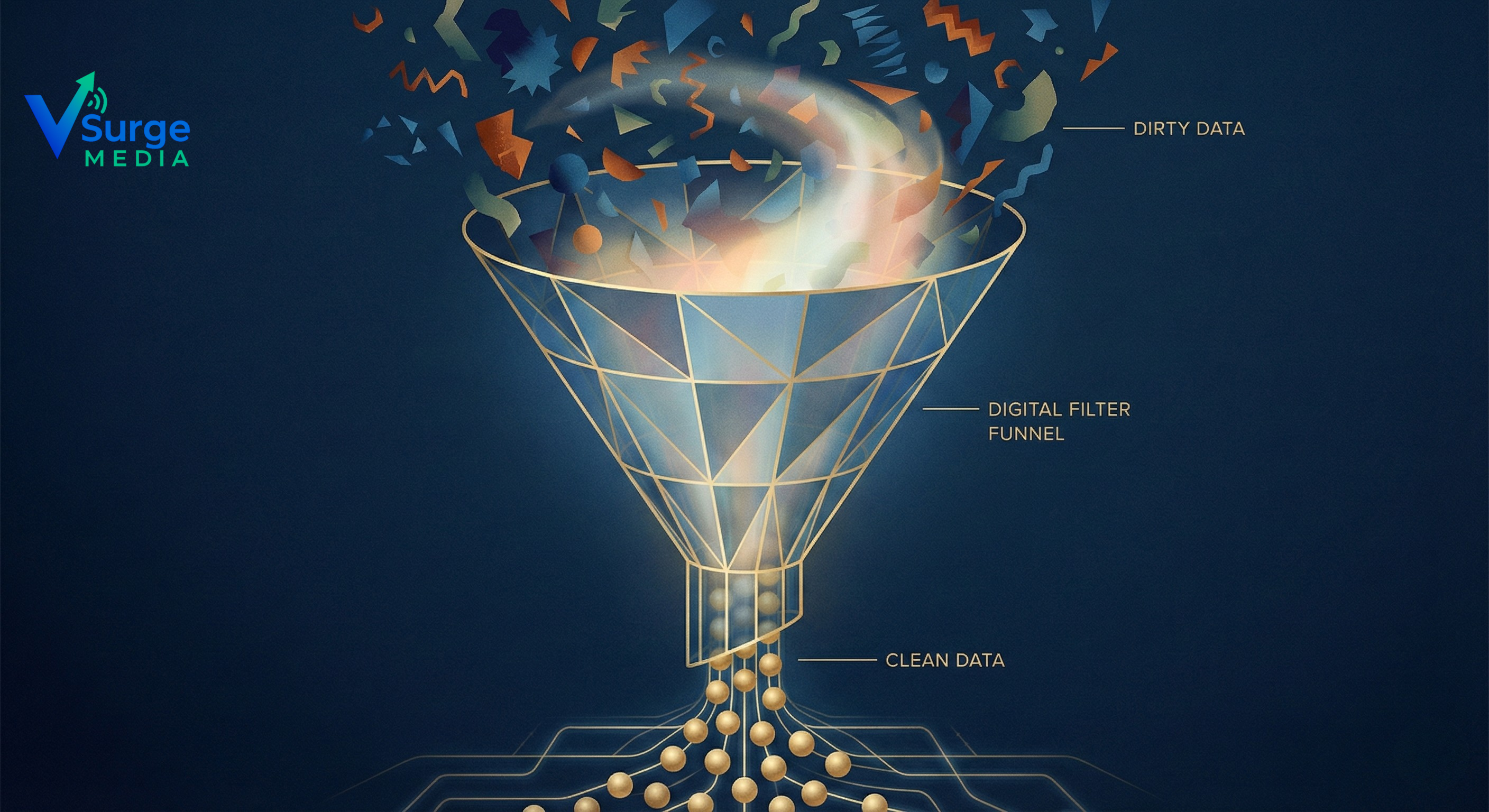
Part 1: The High Cost of Bad Data (Why You Are Bleeding Money)
Before we compare tools, we must understand the stakes. If your customer’s name is “Null” in your CRM, or your inventory count is wrong in your ERP, you aren’t just having a technical glitch; you are bleeding revenue.
The 1-10-100 Rule of Data Quality
This classic concept has become even more critical in the age of AI:
- $1 (Prevention): The cost to verify a record as it is entered.
- $10 (Correction): The cost to fix it later (Data Cleaning).
- $100 (Failure): The cost of doing nothing (Lost customers, failed AI models, compliance fines).
Most businesses are stuck at the $100 stage. They are looking for tools to fix the mess, not prevent it.
The “Hidden” Costs in 2026
- AI Hallucinations: If you feed dirty data into your RAG (Retrieval-Augmented Generation) pipeline, your AI Agent will lie to customers. This damages brand trust instantly.
- Regulatory Fines: With GDPR and CCPA tightening in 2026, holding inaccurate user data is a liability.
- Operational Drag: Data scientists spend 40-50% of their time just cleaning data instead of building models. That is expensive talent wasted on janitorial work.
Part 2: Evaluation Criteria for 2026 Tools
When conducting a data quality management tools comparison, stop looking at vanity features. In the AI era, you need tools that excel in these 6 Dimensions of Data Quality:
- Accuracy: Does the data reflect reality? (e.g., Is that email valid?)
- Completeness: Are required fields missing? (e.g., Missing zip codes).
- Consistency: Is “USA” written as “U.S.A.” in one table and “United States” in another?
- Timeliness: Is the data available when you need it? (Real-time vs Batch).
- Validity: Does it follow the correct format (e.g., regex checks)?
- Uniqueness: Are there duplicates? (Entity Resolution).
The “AI Readiness” Test:
Does the tool simply flag errors for a human to fix (Passive), or does it autonomously correct them using probabilistic reasoning (Active)?
Part 3: The Heavyweights (Legacy Tools Review)
These are the “Old Guard.” Powerful, expensive, and complex. They defined the industry but are now struggling to adapt to the speed of GenAI.
1. Informatica (The Enterprise Giant)
Best For: Fortune 500 companies with massive on-premise legacy systems and unlimited budgets.
- Overview: Informatica is the elephant in the room. Its Intelligent Data Management Cloud (IDMC) is comprehensive but notoriously complex.
- Pros:
- Deep Integration: Connects with virtually any legacy mainframe.
- Governance: Industry-standard security and role-based access.
- Claire AI: Their internal AI engine helps suggest rules.
- Cons:
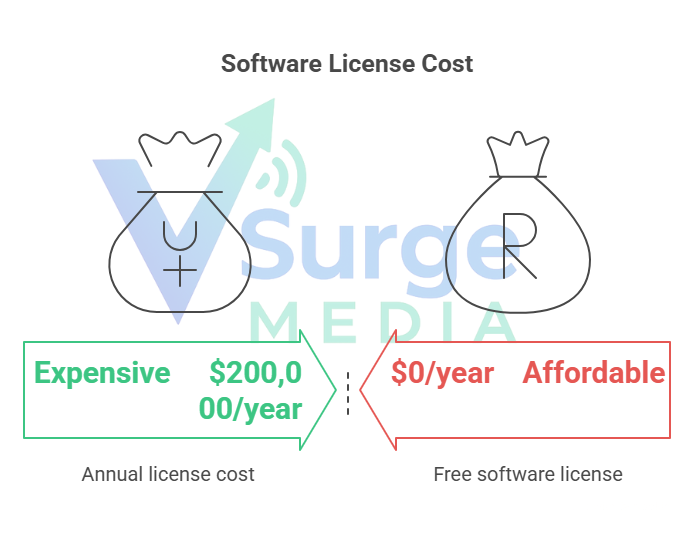
- Cost: Extremely expensive. Licenses can easily exceed $200,000/year.
- Complexity: Requires a dedicated team of certified engineers just to run it.
- UI: The user interface often feels dated compared to modern SaaS.
- Verdict: Overkill for anyone but the biggest players who need on-premise support.
2. Talend (The Developer’s Choice)
Best For: Teams that love open-source roots and have strong Java/Python developers.
- Overview: Now part of Qlik, Talend (Open Studio & Data Fabric) is famous for its ETL capabilities.
- Pros:
- Flexible: Great for custom ETL (Extract, Transform, Load) workflows.
- Community: Strong open-source community for troubleshooting.
- Data Trust Score: A handy metric to gauge dataset health instantly.
- Cons:
- Learning Curve: High. If you don’t know code, you will struggle.
- Resource Heavy: Can be slow when processing massive datasets without proper optimization.
- Verdict: Good for IT teams, bad for business users who want self-service.
3. IBM InfoSphere Information Server
Best For: Banks, Government bodies, and heavily regulated industries.
- Overview: A fortress of data governance.
- Pros:
- Security: Unmatched governance features.
- Scalability: Handles petabytes of data without blinking.
- Cons:
- Speed: Implementation can take 6-12 months.
- UX: Not user-friendly for modern data analysts.
- Verdict: Only choose this if you are a bank.
Part 4: The Disruptors (AI & Observability)
The market is shifting from “Management” (fixing later) to “Observability” (fixing now).
4. Monte Carlo (Data Observability)
The Concept: “New Relic for Data.” It doesn’t just clean data; it alerts you when data breaks.
- Pros: Great for modern data stacks (Snowflake/BigQuery). It uses ML to detect anomalies (e.g., “Why did sales drop to zero at 2 AM?”).
- Cons: It’s primarily a monitoring tool, not a cleaning tool. It tells you the house is on fire but doesn’t necessarily put it out. You still need engineers to resolve the alerts.
5. Ataccama One
The Concept: Self-driving data management.
- Pros: Integrates Data Quality, MDM (Master Data Management), and Data Catalog in one platform. Good use of AI to suggest rules.
- Cons: Still relies on a SaaS subscription model that scales poorly with data volume.
Part 5: The New Alternative – Custom AI Data Agents (Vsurgemedia/Kaiee)
In 2026, smart CTOs are asking: “Why buy a generic tool when I can build a custom agent?”
“While traditional tools rely on manual rules, the demand for AI for data cleaning is skyrocketing because it adapts to new data patterns automatically without constant human oversight.”
At Vsurgemedia, we challenge the traditional SaaS model. Instead of renting a tool like Informatica, we help you build Custom AI Data Agents using our Kaiee Engine.
Why Custom AI Beats Generic SaaS:
| Feature | Generic Tool (Informatica/Talend) | Vsurgemedia Custom AI Agent |
| Logic | Rule-Based (If/Then) | Probabilistic (LLM Reasoning) |
| Cleaning | Flags errors for humans | Auto-Corrects via Context |
| Cost | High Monthly License (Per User/Row) | One-Time Build / Low Maintenance |
| Context | Blind to Business Logic | Trained on YOUR Business Logic |
| Speed | Batch Processing (Slow) | Real-Time Stream Processing |
“When evaluating Informatica vs Talend vs Kaiee, the choice often comes down to budget and agility. While the giants offer robust legacy support, Kaiee offers speed and AI-native intelligence.”
How It Works: The “Kaiee” Methodology
We deploy an AI agent that “watches” your database streams.
- Entity Resolution: It spots that “J. Smith” at 123 Main St and “John Smith” at 123 Main Street are the same person, even without a unique ID.
- Contextual Standardization: It understands that “Bangalore” and “Bengaluru” are the same city and standardizes them based on your preference.
- Anomaly Detection: It alerts your Slack channel only when human intervention is truly needed (e.g., a sudden spike in returns).
Part 6: Implementation Guide – Fixing Your Data in 30 Days
Don’t boil the ocean. If you try to fix all your data at once, you will fail. Here is our 4-Week Roadmap to Data Hygiene.
Week 1: The Audit (Profiling)
- Goal: Know what you are dealing with.
- Action: Use a profiler script (or Vsurgemedia’s Audit Tool) to scan your DB. Identify which columns have the most “Nulls,” duplicates, or format errors.
- Outcome: A “Health Score” for your database.
Week 2: Define the “Golden Record”
- Goal: Standardization.
- Action: Decide your truth. How should a phone number look? (E.164 format?). What is the standard for job titles?
- Outcome: A Data Dictionary and Governance Policy.
Week 3: Automate the Clean-up
- Goal: Fix historical data.
- Action: Deploy an AI Agent (or script) to fix the backlog. Do NOT do this manually. Use LLMs to normalize messy text fields (e.g., converting “vp of sales” and “vice president – sales” to “VP Sales”).
- Outcome: A clean baseline database.
Week 4: Real-Time Governance (The Gatekeeper)
- Goal: Prevent future pollution.
- Action: Set up “Gatekeeper” rules at the point of entry (Web forms, API calls). If a user enters an invalid email, reject it immediately.
- Outcome: Sustainable data quality.
Part 7: Frequently Asked Questions (FAQ)
Q1: Is Data Observability the same as Data Quality?
Answer: No. Data Quality is the condition of the data (Is it accurate?). Data Observability is the ability to understand the health of your data systems (Is the pipeline broken?). You need both.
Q2: Can AI really clean data better than humans?
Answer: For scale, yes. A human might catch a nuance, but they cannot review 1 million rows. AI Agents trained on your specific business logic can achieve 98%+ accuracy in cleaning duties like deduplication and standardization, infinitely faster than a human team.
Q3: How much should I budget for Data Quality tools?
Answer: Enterprise legacy tools often start at $50,000/year. Modern observability tools like Monte Carlo can be similar. However, building a Custom AI Agent with Vsurgemedia typically costs a fraction of the annual license fee of a legacy tool, with lower ongoing costs.
Q4: Does Kaiee work with Salesforce and HubSpot?
Answer: Yes. Kaiee is built with an “API-First” architecture. It sits on top of your CRM or Data Warehouse (Snowflake/Redshift) and cleans data before it is used for reporting or AI models.
Conclusion: Stop Buying Tools, Start Fixing Processes
A tool is only as good as the strategy behind it.
You can buy the most expensive Data Quality Management Tool, but if your culture doesn’t value data, you will fail.
The future isn’t about “Managing” data complexity; it’s about “Automating” data hygiene.
Is your data ready for AI?
If you feed dirty data into your AI models, they will hallucinate.
Clean your data pipeline today with Vsurgemedia.